Sunny Tech 2019 – Focus UX + data = <3
5 août 2019
Cette année encore, l’équipe Design de Kaliop était présente au Sunny Tech. Elle a assisté pendant 2 jours à plusieurs conférences et ateliers traitant de sujets transverses allant des outils, méthodologies de conception jusqu’à la gestion de produit et l’expérience utilisateur…
Floriane, notre Ux/Ui Designer, partage les points clés de la conférence UX + data = <3.

UX + data = <3
J’ai choisi de faire un focus sur la conférence Ux + data = <3 animée par Emmanuelle Marevery. En tant qu’UX Designers, notre rôle est de concevoir le meilleur produit pour l’utilisateur. Et pour cela, connaître et comprendre ce dernier est essentiel. Un point fondamental pour accomplir cet objectif est donc de se baser sur des données.
Vous avez dit DATA ?
La data est un terme utilisé pour qualifier les données qui peuvent circuler sur un réseau. 2,5 trillions d’octets de données sont générées chaque jour dans le monde.
Voici par exemple un diagramme montrant ce qui se passe sur internet en une minute.

Où trouver de la DATA ?
Aujourd’hui, toute entreprise possède de la data (suivi des KPIs, business model…). Malheureusement, elle ne sait pas souvent quoi en faire. Pourtant, la donnée doit être exploitée : elle peut nous permettre de mieux comprendre l’utilisateur, si on l’interprète de la bonne manière, ainsi que de modéliser et prédire des comportements.
Data PROCESS : définir et récolter
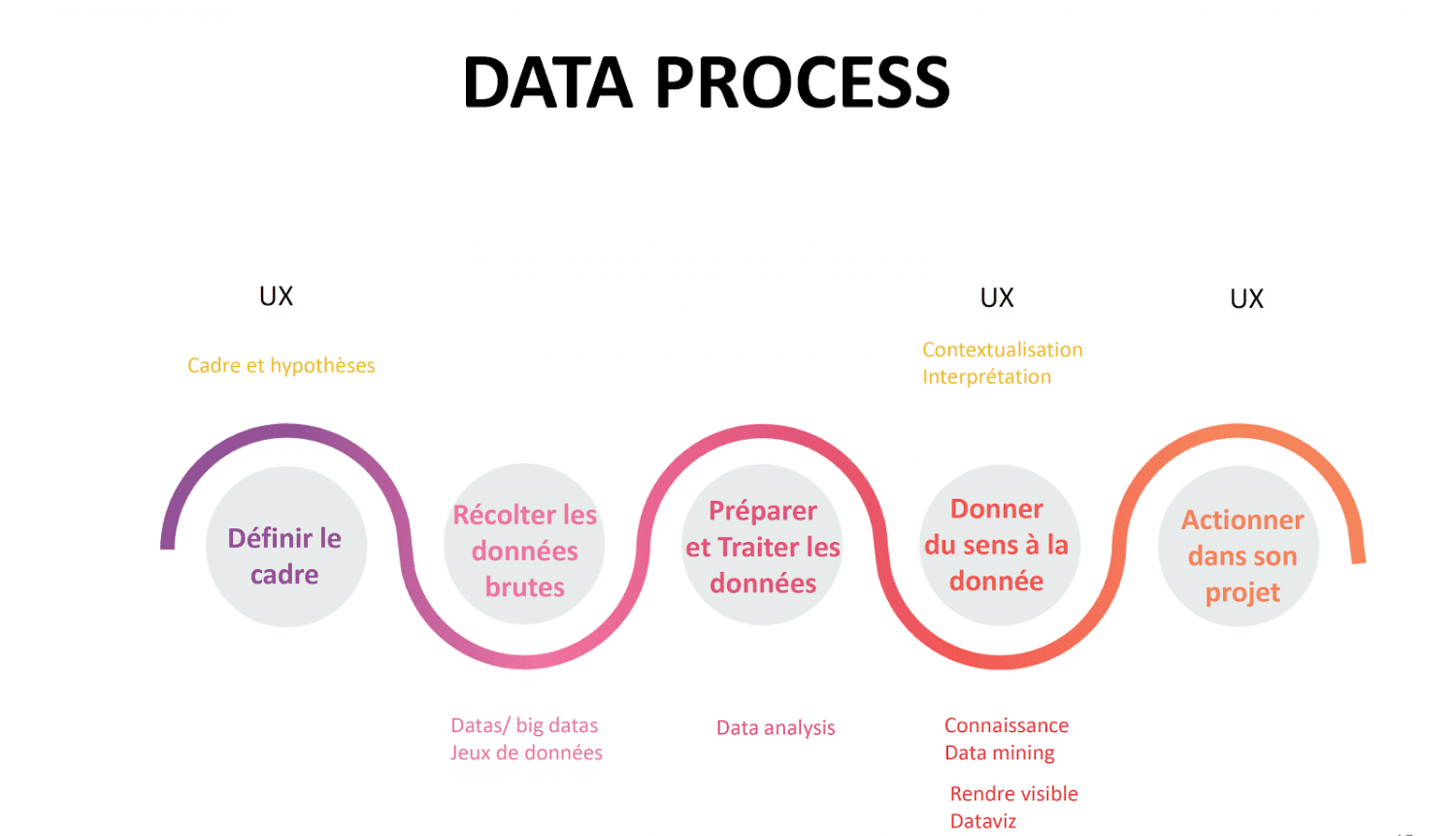
Pour bien utiliser les données, il faut les inclure dans notre process de création, puisqu’à chaque étape elles peuvent trouver leur place :
- Définir le cadre : en phase de cadrage, il faut se demander à quelle problématique doit répondre la data et que faut-il chercher.
- Récolter de la data : il faut partir du principe qu’il y a toujours de la DATA accessible et utile. Oui mais où ? Et par quels moyens ?
On peut trouver de la DATA dans :
- Les données de notre application,
- Les avis clients (store),
- Avec des outils analytics : Google Analytics, Heap, Mixpanel…
- Des contenus et des données déjà analysés (Ipsos, AnswerThePublic, Google Trends…).
Mais vous pouvez aussi créer de la data supplémentaire par :
- Des interviews,
- Des sondages : sur les réseaux sociaux par exemple, ou en utilisant d’autres outils comme Toluna. Bien que payant, c’est un outil très intéressant qui permet de réaliser des sondages sur des communautés ciblées. Ou encore avec la méthode d’Emeline Mercier, qui utilise la complétion de phrases twitter (#sentencecompletion).
Sur un produit purement digital, on peut compléter par :
- De l’A/B testing avec des outils comme Kameleoon, A/B tasty, Beampulse, Optimizely ou Firebase, qui permettent d’avoir de la donnée chiffrée sur des choix et comportements face à des designs différents,
- De l’eye tracking : permet de voir où l’utilisateur porte son regard lors de la navigation,
- Heatmap : chez Kaliop, nous utilisons Hotjar qui est un outil très puissant pour ce genre d’analyse.
On peut donc trouver de la donnée partout, mais que faire avec cette donnée ?
Data PROCESS : pas de données sans contexte
- Traiter de la donnée : une fois la donnée récoltée, il faut la traiter. Des outils sont dédiés à cette tâche : Wordle, Wordart (gratuit, facile), XLSTAT, SPSS, R, Pyton, Orange3.
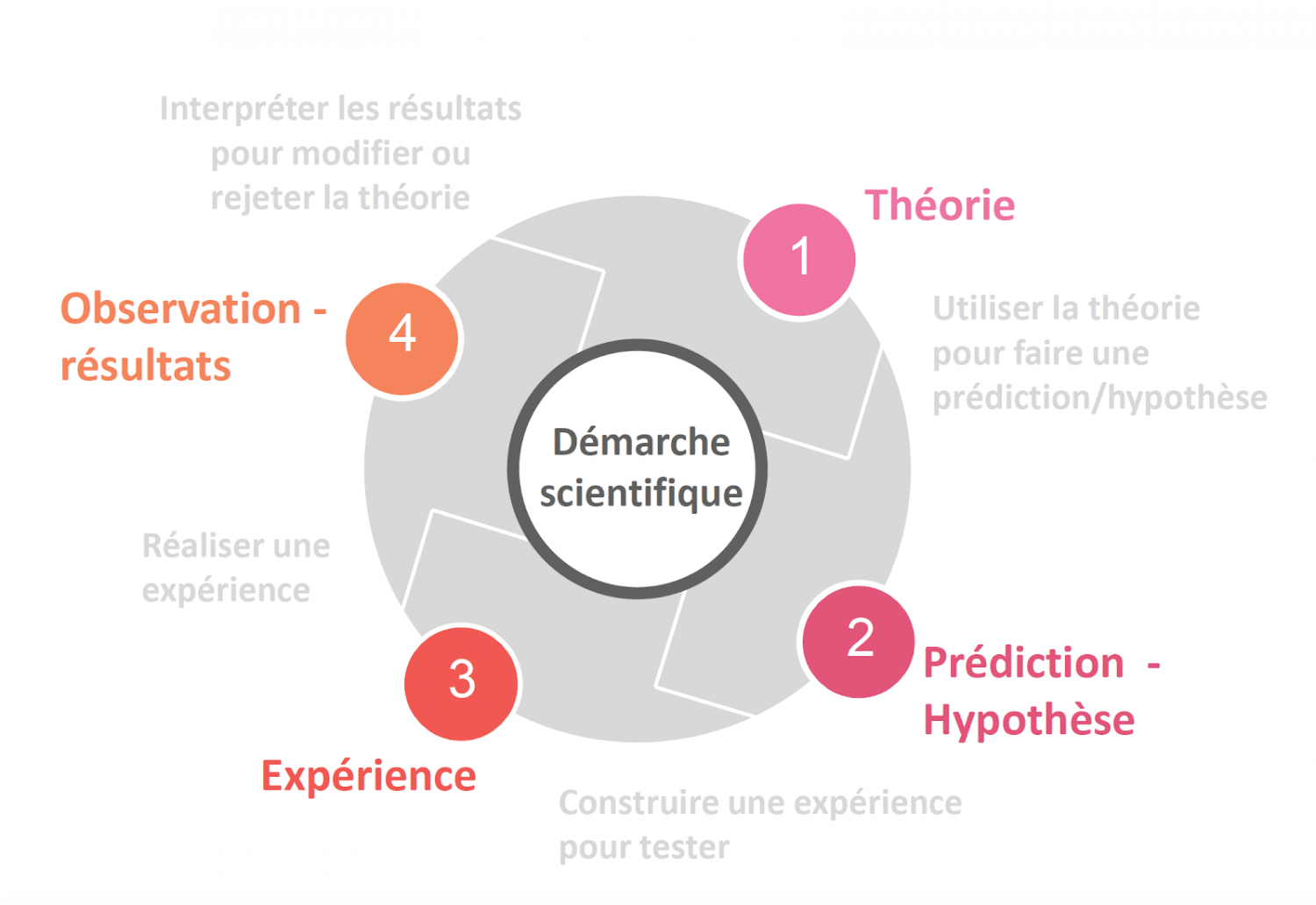
- Donner du sens : cette étape essentielle s’appuie simplement sur une démarche scientifique. Sur la base d’une théorie, on va prédire, faire des hypothèses mais seule l’expérience va nous permettre d’observer des résultats qui pourront ensuite être interprétés. C’est là où l’on va différencier deux types d’analyses : quantitative et qualitative, et deux types de données : Big Data et Thick Data
La quanti s’appuie sur les statistiques, les chiffres, là où la quali s’appuie sur la psychologie. En effet, il faut savoir que 53% des statistiques ne veulent rien dire sans contexte. Prenons l’exemple de la limitation à 80km/h sur les routes : il a été déclaré que « la limitation a produit des résultats historiques, c’est le taux le plus bas jamais enregistré avec une baisse de 5,5% de la mortalité sur les routes ». A première vue, la limitation est largement bénéfique, mais en prenant du recul et en regardant le contexte, il s’avère que le taux de mortalité est en diminution constante, et qu’il y a eu des baisses plus spectaculaires avant. Ainsi, on peut se demander si cette baisse est réellement liée à la limitation à 80km/h. La Big Data est vraie, mais elle est neutre. Tant qu’on n’y apporte pas du sens, ces statistiques ne veulent rien dire.
Derrière ces chiffres, il y a un utilisateur qui utilise un produit dans un certain contexte : géographique, émotionnel, caractériel, environnemental… Pour donner du sens qui ne soit pas faussé, il faut donc contextualiser. La Thick Data est donc tout simplement une approche plus qualitative qui donne du contexte et du sens à la Big Data.
Text mining
Il peut y avoir plusieurs types de données. Mais que faire lorsque la donnée est du texte ?
Pour donner du sens à ce type de données, il existe plusieurs outils. Un des outils présentés que je ne connaissais pas et qui semble intéressant est Q°emotion. Les algorithmes d’Intelligence Artificielle de Q°emotion analysent, classifient et priorisent tout type de messages clients écrits, grâce à la détection des émotions ressenties.
Un nouveau tournant pour le métier d’UX Designer
Nous sommes dans une époque où le métier de Designer évolue et s’impose comme un rôle essentiel au bon déroulement d’un projet. Les données sont donc nécessaires à l’accomplissement d’une bonne expérience utilisateur. Le rôle de Data Scientist est donc de plus en plus étroitement lié à celui du Designer. Nous avons tous compris que pour aller plus loin, il faut dépasser le stade de la récolte massive de Data, et analyser et comprendre ces données pour les transformer en leviers d’amélioration.
Le Duo UX + Data ne fait que commencer et il y a encore beaucoup d’usages à inventer dans nos métiers et de solutions en cours de développement.

Lead Product Designer
Commentaires
