Newsletter personnalisée avec les services cloud AWS et ElasticSearch
17 octobre 2019
Je fais partie d’une équipe qui développe une plateforme de contenu. La plus grande partie de notre trafic vient de notre newsletter. Notre plateforme est construite autour de plusieurs services cloud, et certains sont utilisés pour générer notre newsletter.
Spécifications
- Nos utilisateurs sont intéressés par des domaines différents, et notre contenu est très spécifique. Nous devons envoyer du contenu pertinent pour un utilisateur spécifique, grâce aux informations disponibles sur cet utilisateur. L’objectif est de ne pas envoyer une newsletter trop générique qui ne serait pas pertinente pour un utilisateur qui recherche du contenu rattaché à sa spécialité.
- Notre implémentation doit pouvoir monter en charge facilement. Nous déployons régulièrement notre plateforme sur de nouveaux pays, et nous souhaitons réduire le travail à faire pour chaque nouveau pays.
- La newsletter doit avoir un trigger manuel dans une interface web, avec un outil de debug.
- Nous devons pouvoir expliquer pourquoi un contenu spécifique a été choisi plutôt qu’un autre.
Architecture
Nous utilisons plusieurs services pour générer les newsletters. Le schéma suivant montre comment ils interagissent.
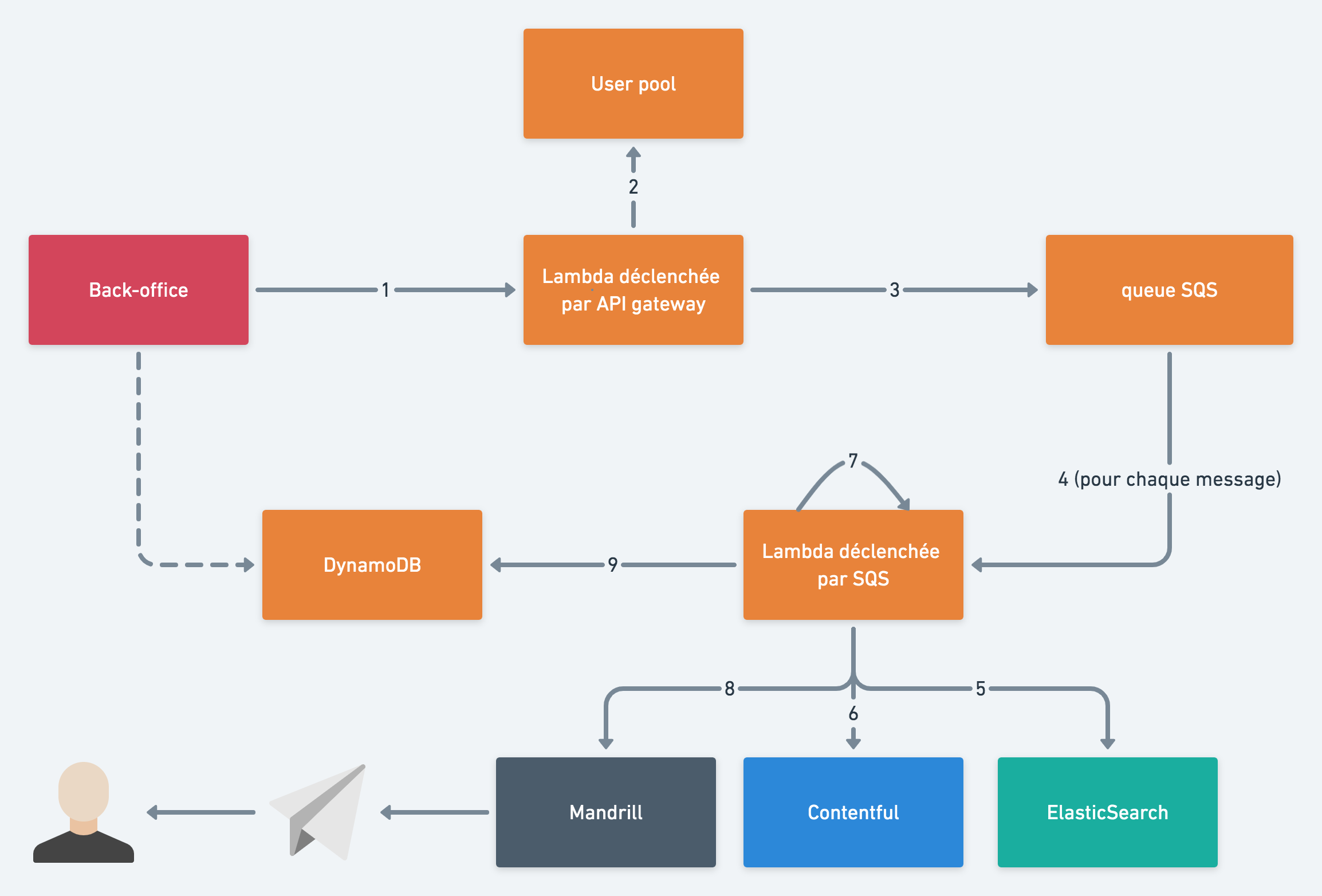
- On déclenche une Lambda AWS depuis notre back-office.
- La lambda récupère les utilisateurs éligibles à la newsletter (en fonction de leurs consentements).
- La lambda envoie un message dans une file SQS (AWS) pour chaque newsletter que l’on souhaite envoyer. Le message contient toutes les informations requises pour un envoi de newsletter (email, centre d’intérêts, etc…).
- Une lambda écoute la file SQS. Chaque fois qu’un message est envoyé dans la file, une lambda est déclenchée pour traiter ce message. De cette façon, nous pouvons résoudre notre problème de montée en charge, car SQS déclenche autant de lambdas que nécessaire pour gérer nos newsletters.
- Quand une lambda est déclenchée, elle envoie une requête à ElasticSearch pour déterminer quel contenu elle doit envoyer à l’utilisateur (plus de détails dans la suite de l’article). ElasticSearch nous permet d’obtenir les identifiants des contenus à envoyer à l’utilisateur.
- La lambda envoie ensuite une requête à Contentful (notre headless CMS où notre contenu est hébergé) avec les identifiants des contenus, pour récupérer toutes les informations dont nous avons besoin (titre, lien, images, etc…).
- Avec les données de Contentful, on génère le template de la newsletter en utilisant Nunjucks (une librairie de template que l’on utilise avec Node.js).
- Grâce aux informations du message et au template de l’email, la lambda envoie une requête à Mandrill (un service d’email transactionnel de Mailchimp) qui s’occupe d’envoyer l’email.
- [OPTIONNEL] La lambda envoie l’état et les erreurs potentielles de la newsletter dans DynamoDB pour pouvoir afficher un feedback à l’utilisateur qui a déclenché l’envoi de la newsletter (nombre de newsletters envoyées, erreurs, etc…).
L’avantage de cette architecture est que tout est découpé en petites unités responsables d’une seule chose. On peut ainsi facilement modifier un service ou le remplacer par un autre sans devoir reprendre tout le processus d’envoi de newsletter.
Déclenchement de la newsletter
L’architecture présentée utilise un back-office pour déclencher une lambda via API gateway pour envoyer les messages dans file SQS. Nous avons choisi cette solution car la mise en place était simple pour ce que nous souhaitions faire, mais on peut utiliser ce que l’on souhaite pour envoyer les messages dans la file SQS (script, web hooks, etc…)
Gérer la personnalisation
Ceci est une explication brève de la façon dont nous utilisons ElasticSearch comme un système de recommandation. Pour plus d’informations, j’ai écrit un article complet sur le sujet : Créer un système de recommandation réversible avec ElasticSearch.
L’idée est de définir une liste de critères et de les ordonner. Par exemple :
- L’utilisateur n’a pas lu l’article
- L’article correspond aux centres d’intérêts de l’utilisateur
- N’importe quelle information booléenne que vous souhaitez tester
On utilise ensuite la fonctionnalité fonction score d’ElasticSearch pour attribuer un poids à chaque critère.
Quand nous envoyons la requête à ElasticSearch, la réponse contient les articles ordonnés par score. La requête inclut également le score de chaque élément dans la réponse. On peut ensuite déduire les critères à partir de ce score.
Ce qu’il faut retenir
Utiliser Lambda et une file SQS pour gérer nos newsletters a bien fonctionné pour nous. Écrire certaines informations dans DynamoDB nous permet d’identifier ce qu’il se passe pour chaque batch de newsletter.
Nous avons utilisé Serverless framework pour déployer la lambda qui déclenche la newsletter ainsi que la lambda qui écoute la file SQS, ce qui nous a simplifié la tâche. Nous avons également utilisé serverless-offline et serverless-offline-sqs pour développer la newsletter, nous permettant de simuler ce qui se passe sur AWS sans déployer.
Nous sommes satisfaits de la solution et nous continuerons d’utiliser ces services AWS.

Expert technique
Commentaires
