Construire une expérience de relations multi-contenus avec Strapi
11 avril 2024
Dans le contexte de refonte d’un site web avec Strapi, nous avons été confrontés à la problématique de la création de relations multi-contenus avec ce CMS. En effet, celui-ci n’autorise que des relations vers un unique type de contenu.
En opposition avec d’autres CMS, Strapi ne permet pas de relier plusieurs types de contenus pour une seule propriété d’un content-type :
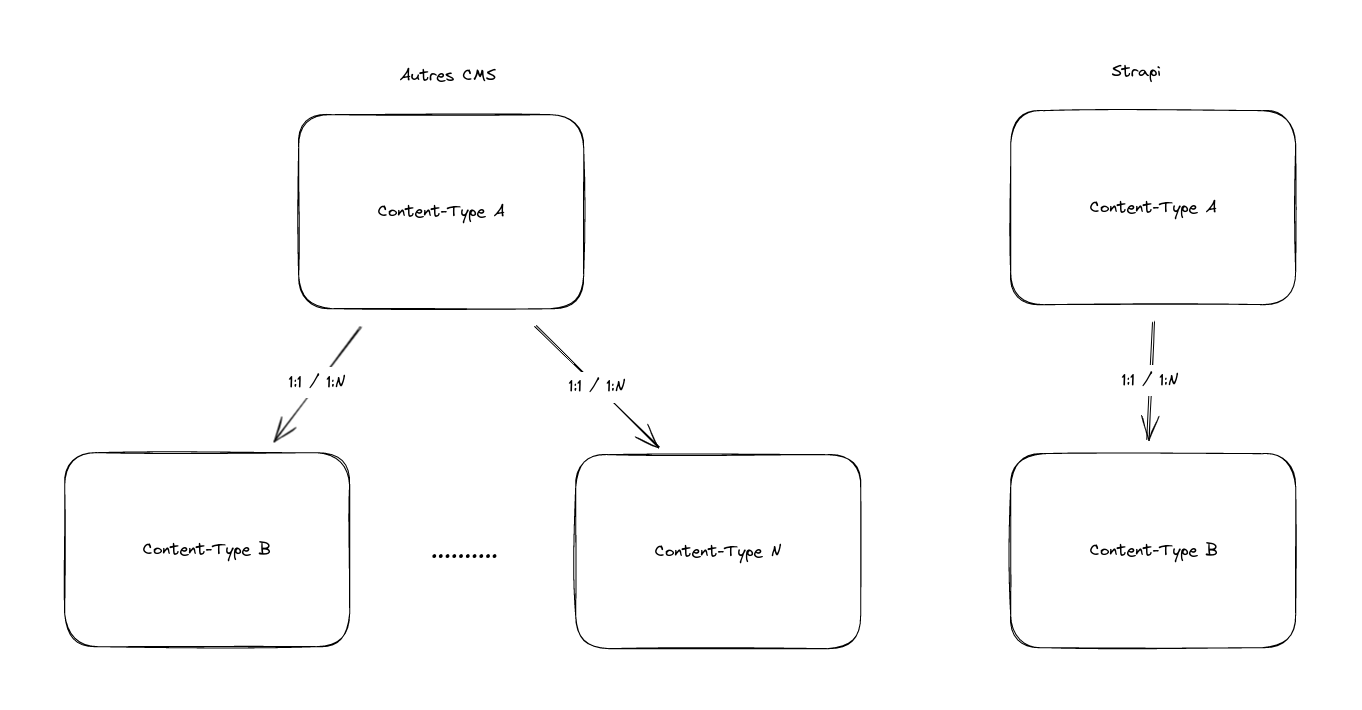
Fig 1. Comparaison avec le marché
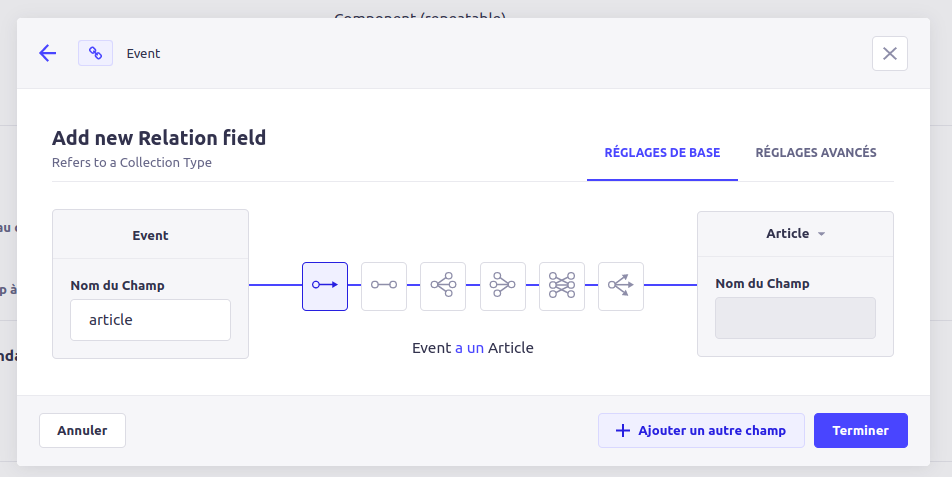
Fig 2. Création d’une relation mono contenu dans Strapi
Comparons rapidement les possibilités des deux CMS :
| Autres CMS | Strapi | |
| Champ requis | X | – |
| Gestion du min/max | X | – |
| Relation multi-contenu | X | – |
| Relation one-to-one | X | X |
| Relation one-to-many | X | X |
| Relation many-to-one | ~ (à créer dans le CT cible) | X |
| Relation many-to-many | ~ (à créer dans le CT cible) | X |
On se rend compte ici qu’il manque 3 features critiques qui sont nécessaires pour la refonte.
Pour pallier ces manques cruciaux, nous avons attaqué le développement d’un plugin Strapi de relation multi content-type, que je nommerai MRCT par la suite (Multi Relation Content Type).
Nous sommes donc partis sur un plugin qui permet d’ajouter un champ custom dans les content types ce qui nous donnera la possibilité, à terme de configurer, par champ, les content types associés pour le champ du content-type.
Headless Experience Conf' - Strapi et l'expérience développeur
Développement du plugin
La première étape du développement a été le proof-of-concept (Preuve de conception), le CMS étant derrière un backend développé avec GraphQL, nous avons mis en place un client Strapi qui permet la récupération des différents contenus. L’approche était de stocker dans un format JSON du contenu, les différents contenus associés, en exploitant leur UID et leur ID et les exploiter dans le client du BFF.
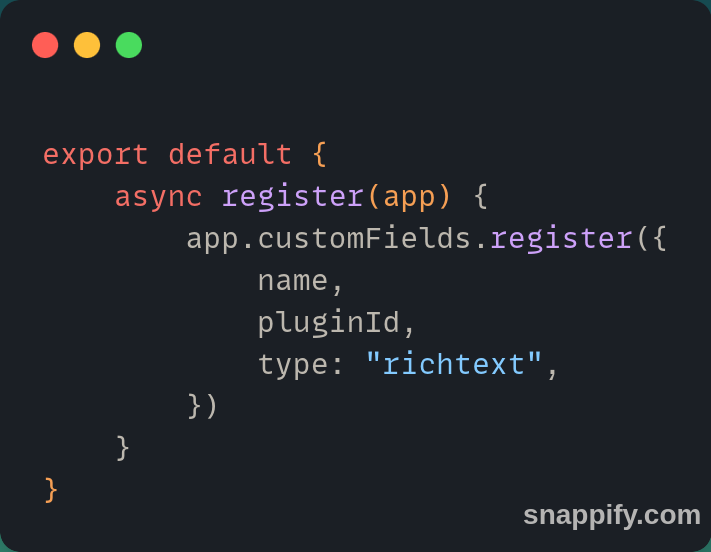
À noter qu’ici, nous avons volontairement mis le type « richText” afin de profiter d’une table qui accepte un gros payload JSON dans le but de ne pas être limité dans la sauvegarde de celui-ci.
S’est ensuivi le développement de la partie backoffice qui permet la contribution de ce champ de relation. Pour cela, nous nous sommes appuyés sur le design system que Strapi nous met à disposition.
Une fois la définition du champ custom établie, passons à la configuration de celui-ci. On souhaite avoir la possibilité de configurer tous les content-types pour lesquels le champ aura une relation, ainsi que les features de bases que Strapi ne propose pas : champ requis (Oui/non), minimum, maximum.
À l’initialisation du backoffice, le plugin appelle une première route d’API custom “listContentTypes” qui permet de récupérer l’intégralité des content-types disponibles pour une relation.
On y ajoute la configuration de base, nous offrant une bien meilleure latitude sur l’exploitation des champs de relation.
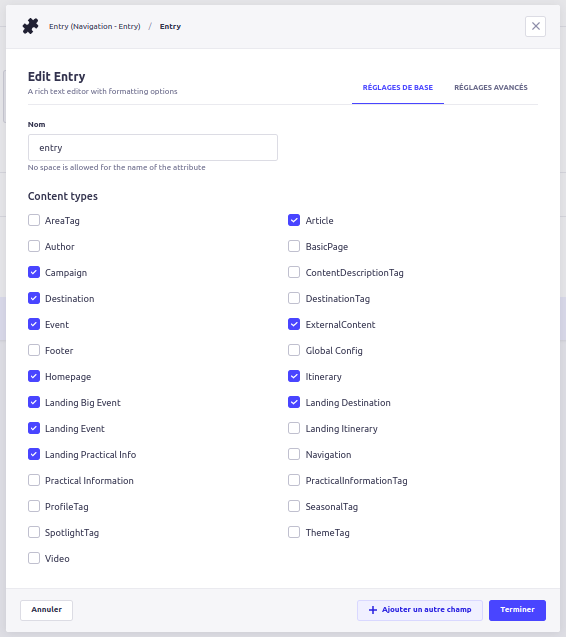
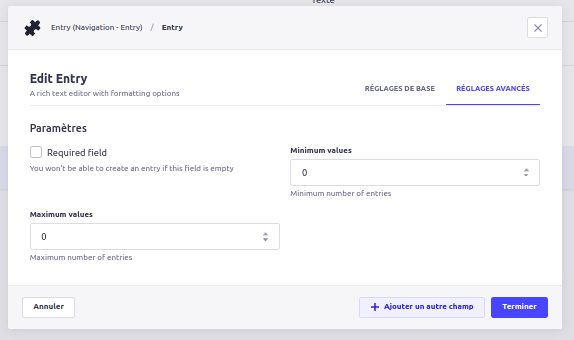
Maintenant que la configuration du custom field est terminée, attaquons nous à l’affichage et la contribution du champ custom. Après quelques itérations de développements sur la partie Backoffice, on arrive à quelque chose qui s’intègre aisément dans le masque de saisie natif de Strapi :
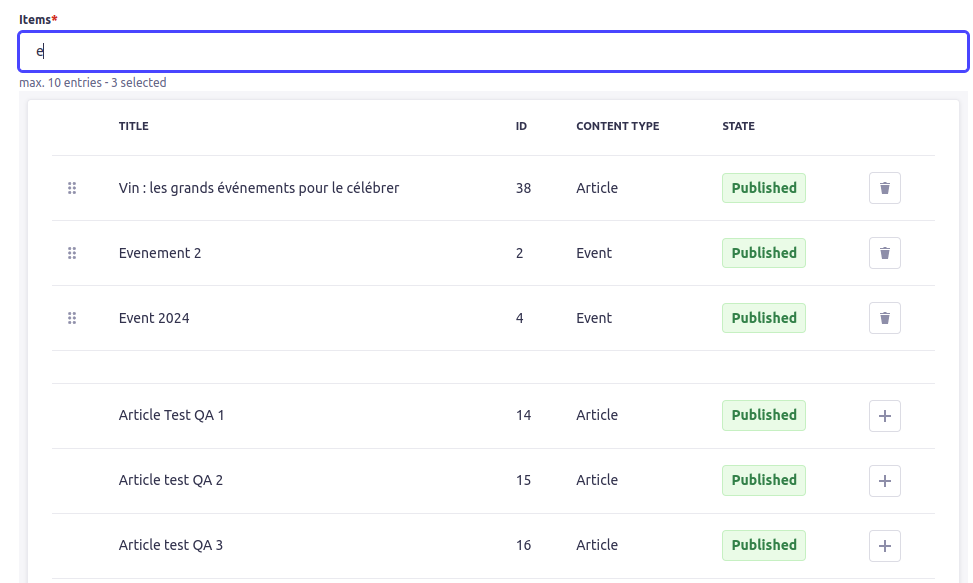
On retrouve sur l’illustration présentée ci-dessus plusieurs choses :
- Le champ de saisie qui permet de rechercher à travers les différents Content Types configurés (en l’occurrence ici “Article” et “Event”).
- Une première zone qui affiche les contenus déjà sélectionnés comme relation. On peut voir leur premier champ String, leur ID, leur content-type et leur état de publication. À souligner que le plugin gère les contenus qui n’ont pas de statuts de publication. Comme pour les composants dans une zone répétable, il est possible de drag and drop pour réordonner les éléments sélectionnés très facilement.
La dernière zone consiste dans les éléments qui peuvent être ajoutés en relation.
Il a ensuite fallu développer des endpoints customs qui permettent de récupérer les différentes données.
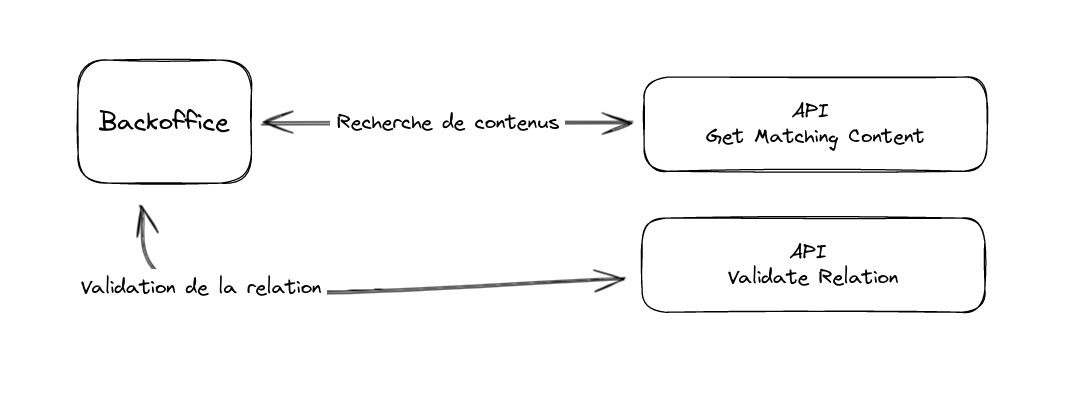
Pour le détail de ces deux endpoints d’API :
- Le endpoint “getMatchingContent” utilise l’entityService interne de Strapi afin de retourner tous les contenus qui correspondent au terme recherché dans le premier champ textuel des content-types recherchés.
- Le endpoint “ValidateRelation” permet de re-valider les contenus sélectionnés lors d’un second affichage de ce champ afin de retirer d’éventuels contenus qui auraient pu être dépubliés ou même supprimés.
L’interface du plugin custom stocke un JSON représente la relation vers ces différents contenus.

À savoir que la présence du champ “MRCT”: true permet d’identifier la présence d’un champ de relation custom dans la réponse d’API de strapi et nous servira dans la seconde partie de cet article.
Consommation du plugin
Nous avons implémenté un client custom Strapi qui vient automatiquement hydrater les contenus dans la mesure du possible. Celui-ci passe par différentes étapes afin d’identifier et d’hydrater les contenus avant de retourner le contenu finalisé :
- Aplatissage (Flatten) de toutes les propriétés de la réponse d’API de Strapi afin de s’assurer une exhaustivité du parcours de champ sans récursivité d’objet,
- Vérification de la présence du flag “MRCT”: true dans le contenu de chaque propriété,
- Validations du contenu JSON présent dans la propriété identifiée,
- Récupération du ou des contenus,
- Remplacement du champ JSON par le contenu hydraté,
- Unflatten des propriétés afin de revenir à une structure identique à l’origine.
Nous pouvons distinguer plusieurs choses dans cette fonction :
- Ajout d’une notion de gestion de profondeur afin d’éviter une récursivité infinie dans la récupération des contenus (le contenu A contient un MRCT vers B qui lui-même contient un MRCT vers A)
- De la configuration annexe est nécessaire pour le fonctionnement de la fonction, comme la définition des content-types dans le backend pour avoir un mapping UID ⇔ Content-Type pour fetcher correctement les contenus associés (gestion du single type/collection type par exemple)
- La non-gestion des contenus identiques hydratés plusieurs fois : de notre côté, on s’appuie sur les dataloaders du BFF dans le but d’exploiter du cache propre à la requête en cours.
Après tout ce développement, on arrive à un contenu qui est correctement hydraté de ses relations.
Conclusion
Ce plugin a été développé sur deux sprints de deux semaines et permet aujourd’hui d’exploiter des composants qui ont plusieurs relations possibles afin d’avoir une vraie dynamique dans la contribution pour le client.
Gardons à l’esprit qu’il reste une amélioration majeure à apporter, qui consiste à la création de hooks de lifecycle autour des contenus qui portent un champ custom MRCT. De cette façon, Strapi portera l’intégralité de la charge de l’hydratation des contenus dans l’API avant de servir la donnée afin qu’elle soit proprement servie dans celle-ci.
Le plugin a été publié sur NPMJS pour le moment, il est en cours de publication sur la marketplace de Strapi, en espérant qu’il soit réintégré par défaut dans les futures versions, pour combler un besoin fonctionnel qui semble indispensable à un CMS.

Expert technique
Commentaires
