Le concept de Backend-for-Frontend
9 janvier 2025
Depuis quelques années, le terme de “Backend-for-frontend” (BFF) est de plus en plus utilisé, principalement pour la migration des architectures techniques vers des approches micro-services, micro-APIs. Ce type d’architecture que nous développons à Kaliop, s’inscrit dans une démarche plus large de replatforming et d’architecture composable, permettant aux entreprises de moderniser leurs systèmes tout en gagnant en flexibilité et en adaptabilité
Ce terme provient d’une approche qui vise à optimiser les communications entre les différentes applications dans un système distribué.
Cela consiste à fournir une communication sur mesure pour chaque type de frontend utilisateur, que ce soit du mobile, du web, de l’IoT… L’idée tend à réduire la complexité du développement en centralisant la logique métier, en agrégeant les différents services et en servant la donnée de la manière la plus flexible possible.
Backend-for-Frontend : le concept, de manière agnostique de la technologie
L’idée repose sur une séparation claire des responsabilités : le BFF s’occupe d’être la couche intermédiaire entre les frontends et la partie “backend” d’un projet concernant les couches de stockages ou autres APIs externes.
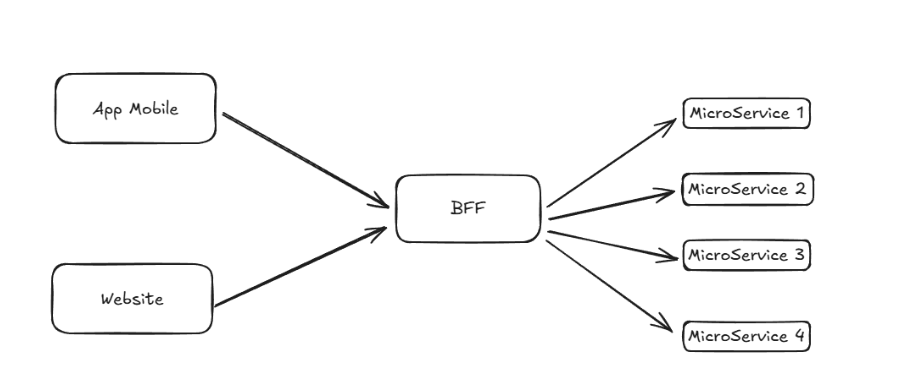
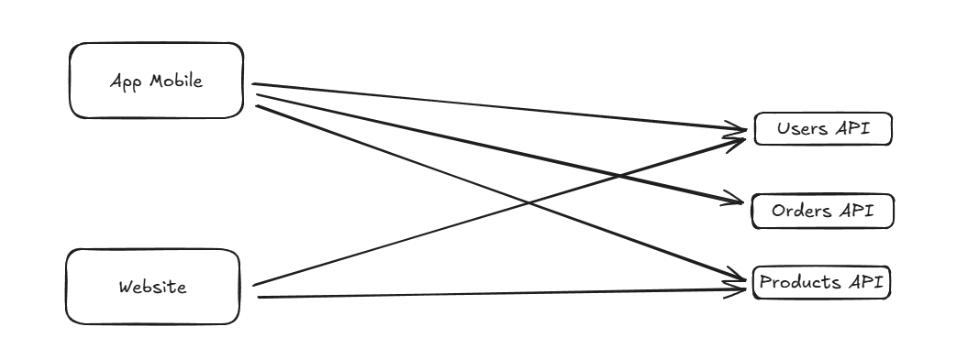
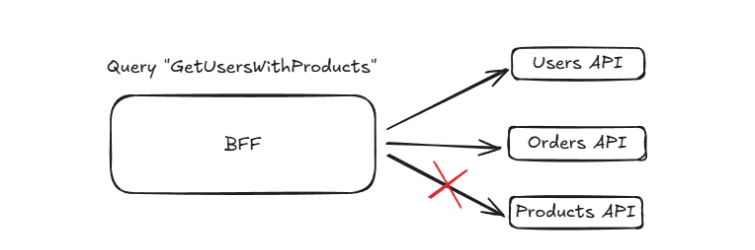
Prenons un scénario où un utilisateur interagit avec une application de gestion de commandes. Sans BFF, le front-end doit appeler séparément les services « Utilisateurs », « Commandes » et « Produits ». Cela entraîne des requêtes multiples ainsi qu’une agrégation manuelle.
Avec un BFF, le front-end envoie une seule requête, et le BFF se charge de communiquer avec chaque service, d’assembler les réponses et de renvoyer un format prêt à l’emploi.
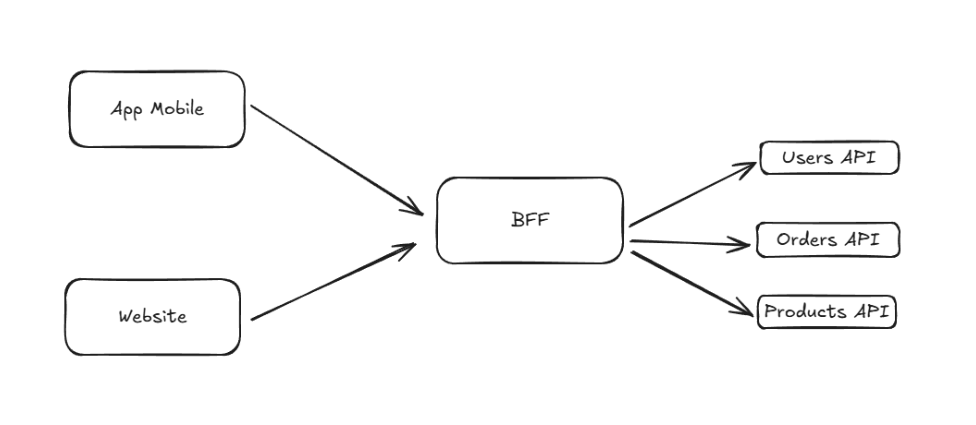
Cette abstraction fonctionne indépendamment de la technologie sous-jacente, qu’il s’agisse de services REST ou GraphQL entre autres… Ce qui change, c’est la manière dont les données sont récupérées, agrégées et renvoyées.
L’objectif est de fournir un point d’entrée unique et optimisé pour chaque type de front-end.
Dans un contexte web, comparons rapidement pourquoi nous utiliserons plutôt GraphQL que du REST.
Vous envisagez de moderniser votre architecture front-back ?
Nos équipes conçoivent et déploient des architectures BFF sur mesure
Parlez-nous de votre projetComparaison entre REST et GraphQL
REST et GraphQL sont deux paradigmes courants pour implémenter une interface.
Là où REST impose des endpoints fixes avec des réponses prédéfinies, GraphQL offre un point d’entrée unique et permet aux clients HTTP de spécifier explicitement les données souhaitées.
Si on reprend notre exemple plus haut, dans tous les cas il faudra implémenter un endpoint qui permet de récupérer à la fois les utilisateurs avec leurs commandes et les produits associés.
Supposons que l’endpoint REST serve ces données :
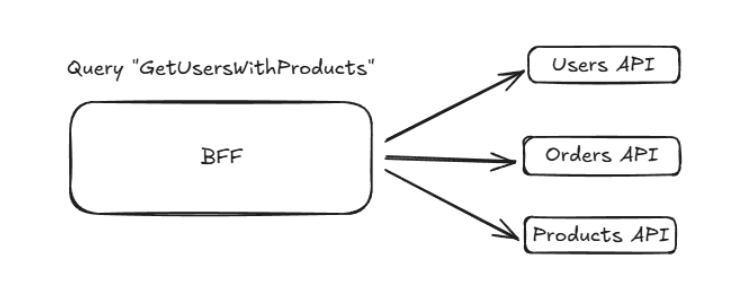
Imaginons que l’application mobile veuille seulement exploiter une partie de la réponse, en l’occurrence ici, les commandes mais sans le détail des produits, l’over-fetching du backend est inévitable dans un contexte REST, vu qu’il impose le modèle de sortie.
En revanche, GraphQL permettant de sélectionner seulement les champs qui ont été demandés et permet de générer les données suivantes :
Cela permet d’éviter “l’over-fetching” de données, de limiter le temps de réponse, d’optimiser la réponse renvoyée.
Conférence le 19 Mars 2026
Headless & front-end Experience : sortir de la jungle des frameworks
S'inscrire gratuitementMise en application
GraphQL, créé par Facebook pour pallier les problématiques évoquées plus haut concernant REST, offre un écosystème complet avec une communication front-back déjà établie et normée, une pléthore d’outils qui permettent le monitoring, le cache, la fédération d’APIs sous-jacentes et j’en passe.
L’implémentation commence par la définition d’un schéma, qui expose des modèles de données, fortement typés. Si on reprend notre exemple d’e-commerce, cela pourrait se traduire par ce schéma la :
Cette query permet au front-end de demander précisément les informations nécessaires.
Une fois le schéma défini, on peut passer à la logique métier à travers les “resolvers”. Ceux-ci reçoivent les arguments passés et vont chercher les différentes données pour satisfaire le type de retour défini par le schéma
Jusque là, il s’agit d’une mise en place classique d’un service backend. Comme évoqué plus haut, GraphQL étant en premier lieu un langage de requête, il permet de sélectionner seulement les champs nécessaires. Dans l’exemple ci-dessous, la query front associée ne sélectionne que certains des champs du produits
Admettons que le champ “relatedProducts” d’un produit est coûteux à servir, le fait de ne pas “sélectionner” le champ permet de s’affranchir de ce temps de traitement (en comparaison à une API Rest).
Apollo : L’écosystème complet pour GraphQL
Chez Kaliop, nous utilisons Apollo qui est une des implémentation de GraphQL robuste et pertinente, largement démocratisée dans la communauté.
A noter l’un des avantages majeurs d’Apollo est son système de gestion de cache. Plusieurs caches sont possibles :
- Du cache côté client avec le client Apollo
- Du cache au niveau de la réponse du serveur GraphQL, notamment avec du cache LRU
- Du cache entre les resolvers et d’éventuels API externes, via les “dataloaders”
- Du cache des queries nommées “Automatic Persisted Queries” en améliorant les performances réseaux
Parmi les usages avancés, GraphQL permet d’augmenter un schéma via un autre schéma et ainsi éviter l’effet monolithe, il s’agit du “schema stitching”.
Pour finir, de par la nature “Schema first” de l’approche, il est possible de faire du “mocking”, c’est-à-dire, générer des données temporaires, afin de faire avancer le ou les front-end avant même l’implémentation finale du BFF.
Backend for Frontend : Une approche optimisée pour une architecture moderne
L’apport d’un BFF est indéniable, de par la normalisation des données servies, la faculté à établir une communication propre et optimisée entre les différentes couches de votre projet et une meilleure séparation des responsabilités. Un BFF avec une implémentation via Apollo GraphQL permet une optimisation des performances, que ce soit au niveau réseau pour éviter l’over fetching et avec les différentes possibilités de cache.
Une communication facilitée entre les développeurs frontend & backend est souvent observée de part l’appropriation d’un schéma commun.

Expert technique
Commentaires
