L’IA générative dans les applications modernes
10 décembre 2024
Le 30 novembre 2022 OpenAI leader mondial de la recherche dans l’intelligence artificielle (IA) a déployé sa nouvelle plateforme ChatGPT. La sortie de cette plateforme d’IA générative a un véritable effet de bombe. Ceci marquera à tout jamais un tournant dans la manière dont nous interagissons avec la technologie et exploitons l’IA.
De nos jours, un grand nombre d’entreprises cherchent à incorporer l’IA générative dans leurs processus. Certaines suivent le phénomène pour capter l’intérêt et profiter de l’effet de mode, sans stratégie concrète. D’autres entreprises utilisent l’IA pour innover, optimiser leurs processus et générer une valeur durable. En constatant les résultats encourageants du RAG (Retrieval-Augmented Generation), une multitude d’entreprises, ont réussi à se distinguer grâce à cette technique. Elle optimise les réponses des chatbots en combinant génération de texte et collecte d’informations dans des bases de données. Il est indéniable que les sociétés qui ont opté pour cette technologie se distinguent des autres.
Cet article examine l’intégration de l’intelligence artificielle au sein des entreprises et ses multiples applications concrètes. Nous commencerons par décrire le fonctionnement d’un Chatbot, en précisant le processus de vectorisation des questions posées par l’utilisateur. Par la suite, nous traiterons de la création de la base de connaissances, un élément crucial pour fournir des réponses précises. Nous aborderons aussi la recherche sémantique, facilitant la découverte des informations les plus pertinentes, avant de se diriger vers un modèle de langage avancé qui produit la réponse finale.
Adoption de l’IA générative
Depuis 2017, OpenAI, leader mondial de l’intelligence artificielle, travaille sur des modèles dits de langage avancé.
En 2018, ils publient un article nommé “Improving Language Understanding by Generative Pre-Training” qui signera le début des modèles GPT. En 2020, ils publient GPT-3, entraîné sur des millions de données issues d’internet pendant près d’un an. Ensuite, en 2021, le grand public s’émerveille devant la sortie de DALL-E, un modèle de génération d’image numérique complexe.
En 2022, OpenAI lance ChatGPT, basé sur GPT-3.5, pour rendre ces modèles de langage accessibles à tous. Le modèle démontre rapidement des capacités de conversation et de génération de texte qui surprennent par leur sophistication et leur cohérence. Dans le monde entier, les utilisateurs adoptent rapidement cet outil, l’intégrant dans diverses applications et secteurs d’activité.
L’impact croissant de l’IA générative dans les secteurs clés
Aujourd’hui, l’intelligence artificielle joue un rôle majeur dans diverses industries comme :
- La santé où les modèles d’IA sont utilisés pour diagnostiquer des maladies, analyser des images médicales ou encore et personnaliser les traitements.
- En finance, l’IA est employée pour détecter les fraudes, évaluer les risques, et automatiser les transactions financières.
- Le commerce en ligne, pour lequel des systèmes de recommandation, alimentés par l’IA, améliorent l’expérience d’achat en proposant des produits pertinents en fonction des préférences des utilisateurs.
- Le transport où les véhicules autonomes et les systèmes de gestion du trafic utilisent l’IA pour améliorer la sécurité et l’efficacité des transports. L’analyse prédictive aide à prévenir les accidents et à gérer la circulation de manière proactive.
- Le divertissement dans lequel les plateformes de streaming et de réseaux sociaux utilisent l’IA pour personnaliser le contenu, recommander des films, des séries et de la musique en fonction des goûts des utilisateurs. La création de contenu génératif dans les jeux vidéo et les films commence également à émerger avec des modèles comme DALL-E ou StableDiffusion.
L’introduction de ChatGPT a été un catalyseur pour l’adoption de l’intelligence artificielle dans de nombreux domaines. Son succès a démontré la puissance de l’IA générative et a ouvert la voie à de nouvelles innovations. Aujourd’hui, l’IA continue de transformer les applications modernes, offrant des solutions plus intelligentes, plus rapides et plus personnalisées pour répondre aux besoins complexes de notre société en constante évolution.
Comment fonctionne un Chatbot intelligent ?
Les chatbots étaient généralement construits en utilisant des systèmes de règles (arbre de décision) ou des modèles statistiques basiques. Ils avaient la capacité de répondre à des interrogations fréquentes et de suivre des scripts préétablis, mais ils manquaient souvent de souplesse et de compréhension du contexte, ce qui restreignait leur aptitude à gérer des discussions complexes ou imprévues. Les utilisateurs se retrouvaient fréquemment frustrés lors des interactions en raison de réponses incohérentes ou hors sujet.
Avec l’introduction des Modèles de Langage Avancé ou Large Language Models en anglais, plus communément appelés LLMs, les chatbots ont fait un bond spectaculaire. Cela concerne notamment leur compréhension et leur génération de langage naturel. Ces modèles peuvent gérer les subtilités de la langue, préserver le contexte lors de longs débats et produire des réponses plus pertinentes et spontanées.
Ils utilisent une base de connaissances pour fournir des réponses précises et utiles. Lorsqu’un utilisateur pose une question, le chatbot utilise la technique du Retrieval-Augmented Generation (RAG) pour consulter cette base de connaissances et trouver les informations pertinentes.
Le RAG consiste à combiner la collecte d’informations et la production de texte afin d’améliorer la qualité des réponses. Il intègre les données collectées grâce à un LLM, offrant ainsi un cadre riche pour une compréhension approfondie de la question.
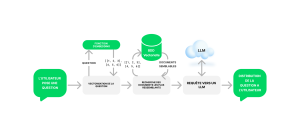
Le LLM utilise ce contexte pour générer une réponse appropriée, qu’il présente ensuite à l’utilisateur. Cela permet au chatbot de fournir des réponses plus précises et contextualisées.
Quand une question est posée, les étapes sont les suivantes :
- Vectorisation de la question,
- Recherche sémantique dans la base de connaissances,
- Requête vers un LLM et distribution de la réponse à l’utilisateur final.
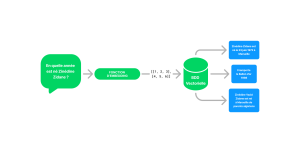
Vectorisation de la question
La structure mathématique d’un vecteur consiste en une liste ordonnée de nombres qui représente des données. En règle générale, en intelligence artificielle, et plus spécifiquement dans le domaine de la compréhension et du traitement du langage naturel, les vecteurs sont fréquemment employés afin de représenter de manière numérique des mots, des phrases ou d’autres types de données textuelles.
Tous les mots d’une phrase sont transformés en un vecteur grâce à une méthode connue sous le nom d’encodage vectoriel ou embedding. Ces vecteurs captent les propriétés sémantiques et contextuelles des mots, ce qui permet aux modèles d’intelligence artificielle de mieux comprendre et traiter le texte. Chaque vecteur symbolise un point dans un espace à trois dimensions (3D) où la proximité correspond à une signification proche. Ainsi, les mots qui ont le plus de similitudes sémantiques reçoivent des vecteurs très similaires en termes de valeurs.

Le choix de la fonction d’embedding est essentiel, car il influence la qualité de la représentation vectorielle et, par conséquent, la performance de notre application. Une bonne fonction d’embedding capture les relations sémantiques et contextuelles entre les mots, permettant au modèle de comprendre les nuances et les significations implicites.
Les modèles d’embeddings comme text-embedding-ada-002 d’OpenAI, qui sont entraînés sur de nombreux langages, offrent une large couverture linguistique, tandis que les modèles spécialisés comme ceux basés sur CamemBERT pour le français sont optimisés pour capturer les nuances et les spécificités d’un seul langage, fournissant ainsi des représentations plus précises et pertinentes pour ce contexte particulier.
Création de la base de connaissance
L’indexation de contenu dans une base de connaissances vectorielle comme ChromaDB, FAISS ou encore Qdrant, consiste à transformer des documents texte en vecteurs pour faciliter la recherche sémantique. Prenons l’exemple d’un article Wikipedia.
Le texte est d’abord séparé en segments appelés chunks afin de l’indexer. Une méthode naïve de génération de chunks consiste à fragmenter le texte de manière arbitraire en morceaux de taille fixe, sans prendre en considération les transitions logiques ou contextuelles entre eux. L’avantage de cette méthode réside dans sa simplicité d’installation, tandis que l’inconvénient réside dans le fait que chacun de ces morceaux peut perdre en signification sans avoir le contexte des morceaux précédents et suivants.

Cependant, une stratégie plus avancée utilise un chevauchement ou overlap entre les chunks pour préserver le contexte et les liens sémantiques. Par exemple, chaque chunk peut contenir une partie du chunk précédent et suivant, garantissant ainsi une continuité contextuelle. Cette méthode créera de la redondance dans la donnée stockée et donc par conséquent nécessitera un peu plus de stockage.
Ces chunks sont ensuite vectorisés individuellement et stockés dans la base de données vectorielle aux côtés des metadatas représentant des données structurées concernant le document en question comme son id et son titre. Cette approche améliore la précision de la recherche en permettant au modèle de mieux comprendre et relier les informations pertinentes réparties sur plusieurs chunks.
Recherche sémantique
Une fois le vecteur créé à partir de la question, vient l’étape de la recherche sémantique dans la base de connaissances. Ce vecteur est ensuite comparé à l’ensemble des vecteurs stockés dans la base de données représentant les documents disponibles.
Pour trouver les documents les plus pertinents, des mesures de similarité, comme la distance cosinus, sont utilisées pour évaluer la proximité entre le vecteur de la question et ceux des documents. Les documents dont les vecteurs sont les plus proches de ceux de la question sont considérés comme les plus pertinents.
Plus on récupère de documents pour une question donnée, plus on a de chances de s’éloigner du contenu sémantique de la question et, par conséquent, de provoquer une hallucination au LLM. A contrario, on pourrait vouloir lui donner un peu plus de contexte pour l’aider à ce qu’il soit plus créatif. Le choix du nombre de documents récupérés pour une question donnée dépend donc fortement du contexte applicatif et de la manière dont la donnée a été découpée. Plus on récupère de documents pour une question donnée, plus on a de chances de s’éloigner du contenu sémantique de la question et, par conséquent, de provoquer une hallucination au LLM. A contrario, on pourrait vouloir lui donner un peu plus de contexte pour l’aider à ce qu’il soit plus créatif. En 2022, OpenAI lance ChatGPT, basé sur GPT-3.5, pour rendre ces modèles de langage accessibles à tous.
Requête vers un LLM
Le choix du modèle de LLM pour l’étape de génération de la réponse est crucial et peut se faire entre des modèles open source, comme LLaMA, et des modèles propriétaires, comme GPT-4.
Les modèles open source, tels que LLaMA, offrent l’avantage de la transparence et de la flexibilité. Les utilisateurs peuvent accéder au code source, adapter le modèle à leurs besoins spécifiques, et le déployer sur leurs propres serveurs. Ce qui peut être bénéfique pour des raisons de confidentialité et de contrôle des données.
En revanche, les modèles propriétaires comme GPT-4, tendent à être plus performants en termes de compréhension et de génération de texte grâce à des ressources plus importantes. Cependant, ils sont souvent associés à des coûts d’utilisation plus élevés et à des restrictions sur l’accès et la personnalisation.
Le choix entre ces types de modèles dépendra donc des priorités de l’utilisateur, telles que la performance, la flexibilité, la confidentialité des données, et les considérations budgétaires.
Vers une nouvelle ère de chatbots
La création de chatbots intelligents est devenue de plus en plus accessible grâce à la prolifération des bases de données vectorielles. Ces bases de données permettent une gestion efficace et rapide des informations contextuelles, améliorant ainsi la pertinence des réponses générées. Leur principal avantage réside dans la capacité à traiter et à récupérer des données complexes avec une grande précision, bien que leur utilisation puisse nécessiter une gestion attentive des ressources et des compétences techniques spécifiques.
Cependant, des acteurs comme LangChain commencent à émerger pour faciliter tout cela. L’intégration de ces bases de données dans ces outils simplifie considérablement l’implémentation des chatbots, en offrant des méthodes pour abstraire les prompts, gérer les requêtes vers les bases de données et faciliter la communication avec divers LLMs. Ces avancées permettent non seulement de réduire les barrières techniques à l’entrée, mais aussi de créer des chatbots plus performants et polyvalents, ouvrant la voie à des applications innovantes dans de nombreux domaines.

Commentaires
